Stable Diffusion
4210 readers
10 users here now
Discuss matters related to our favourite AI Art generation technology
Also see
Other communities
founded 1 year ago
MODERATORS
1
This is a copy of /r/stablediffusion wiki to help people who need access to that information
Howdy and welcome to r/stablediffusion! I'm u/Sandcheeze and I have collected these resources and links to help enjoy Stable Diffusion whether you are here for the first time or looking to add more customization to your image generations.
If you'd like to show support, feel free to send us kind words or check out our Discord. Donations are appreciated, but not necessary as you being a great part of the community is all we ask for.
Note: The community resources provided here are not endorsed, vetted, nor provided by Stability AI.
#Stable Diffusion
Local Installation
Active Community Repos/Forks to install on your PC and keep it local.
Online Websites
Websites with usable Stable Diffusion right in your browser. No need to install anything.
Mobile Apps
Stable Diffusion on your mobile device.
Tutorials
Learn how to improve your skills in using Stable Diffusion even if a beginner or expert.
Dream Booth
How-to train a custom model and resources on doing so.
Models
Specially trained towards certain subjects and/or styles.
Embeddings
Tokens trained on specific subjects and/or styles.
Bots
Either bots you can self-host, or bots you can use directly on various websites and services such as Discord, Reddit etc
3rd Party Plugins
SD plugins for programs such as Discord, Photoshop, Krita, Blender, Gimp, etc.
Other useful tools
- Diffusion Toolkit - Image viewer/organizer that scans your images for PNGInfo generated.
- Pixiz Morphing - Easily transition between 2 photos.
- Bulk Image Resizing Made Easy 2.0
#Community
Games
- PictionAIry : (Video|2-6 Players) - The image guessing game where AI does the drawing!
Podcasts
- This is Not An AI Art Podcast - Doug Smith talks about Ai Art and provides the prompts/workflow on his site.
Databases or Lists
- AiArtApps
- Stable Diffusion Akashic Records
- Questianon's SD Updates 1
- Questianon's SD Updates 2
- SW-Yw's Stable Diffusion Repo List
- Plonk's SD Model List (NSFW)
- Nightkall's Useful Lists
- Civitai - Website with a list of custom models.
Still updating this with more links as I collect them all here.
FAQ
How do I use Stable Diffusion?
- Check out our guides section above!
Will it run on my machine?
- Stable Diffusion requires a 4GB+ VRAM GPU to run locally. However, much beefier graphics cards (10, 20, 30 Series Nvidia Cards) will be necessary to generate high resolution or high step images. However, anyone can run it online through DreamStudio or hosting it on their own GPU compute cloud server.
- Only Nvidia cards are officially supported.
- AMD support is available here unofficially.
- Apple M1 Chip support is available here unofficially.
- Intel based Macs currently do not work with Stable Diffusion.
How do I get a website or resource added here?
*If you have a suggestion for a website or a project to add to our list, or if you would like to contribute to the wiki, please don't hesitate to reach out to us via modmail or message me.

2
3
4
13
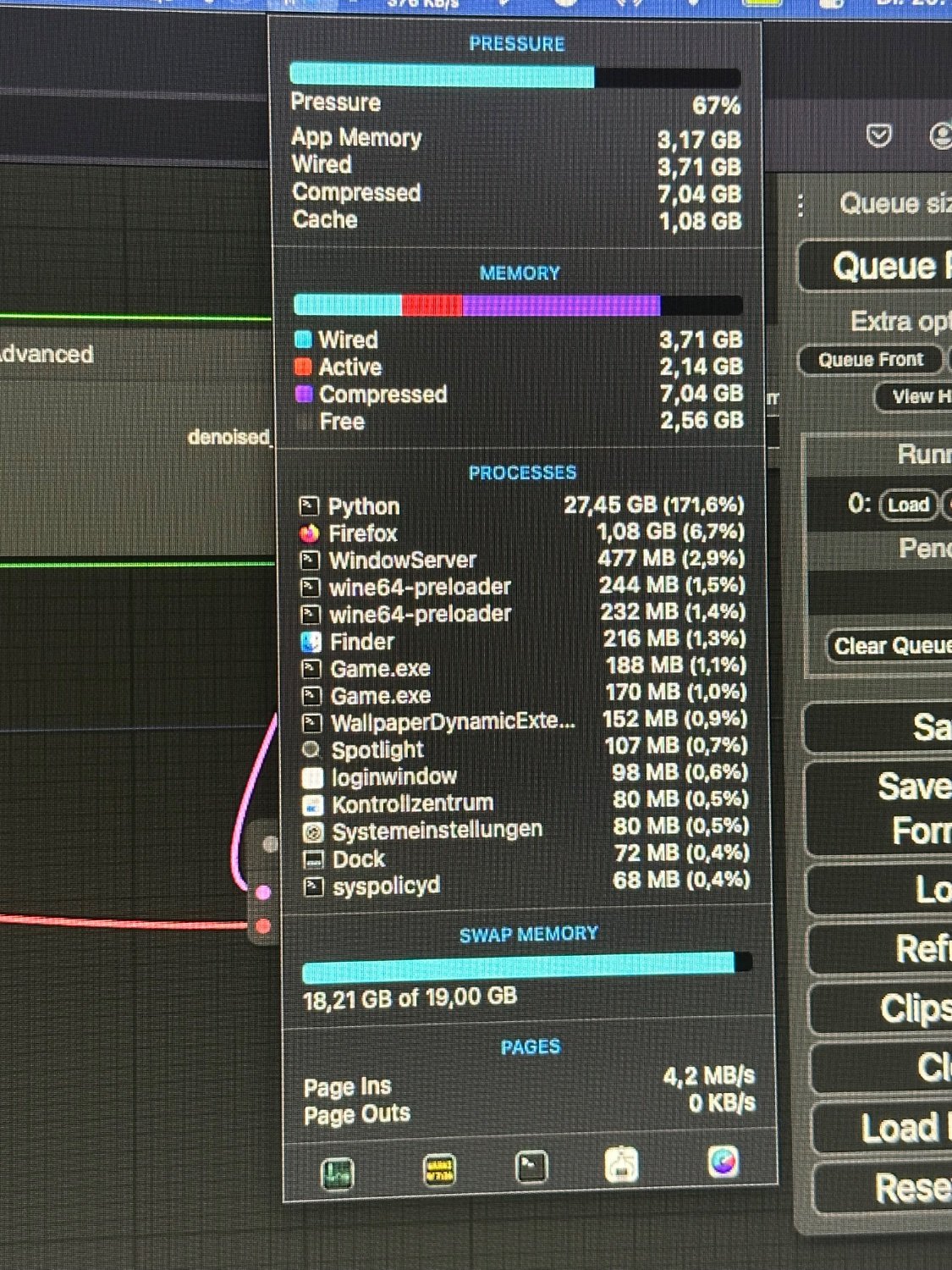
Flux via ComfyUI on M1 MacBook Air 16 GB RAM 256GB - a second later it threw an error and died
(lemmy.world)
Has anyone of you stumbled upon any information on how to get it running on machines like mine, or does it just not have enough power?
5
7
8

10
11
12
13
14
15
53
Linux Foundation Welcomes the Open Model Initiative to Promote Openly Licensed AI Models
(www.linuxfoundation.org)
16
17
18
19
20
21
22
23
From The Hugging Face Model Card:
Not Ready
This is a WIP and not ready for use. This is an early testing version for research and development. You may know what this is and how to use it, if so, feel free, but it will change as I continue to develop it. I plan to do many updates to it frequently. So you may want to set a revision if you intend to use it anyway.
What is this?
FLUX.1-schnell is an amazing distilled model with an apache 2.0 license. However, it is not finetunable. LoRAs, IP adapters, control nets, etc, cannot be trained on it because it is distilled. The goal of this project is to finetune a non-distilled version of it that can be used as a training base to train adapters for FLUX.1-schnell.
Current Issues
Since we are breaking the distillation, this model will need many steps and guidance to produce good results. Currently, this model, like the schnell version, does not have guidance embeddings. Because of this (and possible other factors) images generated with this model will not look great. However, this hopefully will not affect training, since guidance is not used during training. The things trained on this model are intended to be used on the schnell version anyway. I am working on training guidance embeddings for it, but hopefully it will work as a training base without them.



{kind=link}
25
view more: next ›