I'm not sure if this is the best community to post in, but I just bought a used computer and slotted in an RX480 as the GPU. I installed KDE Neon 5.27 on it, and it worked flawlessly for 2 days.
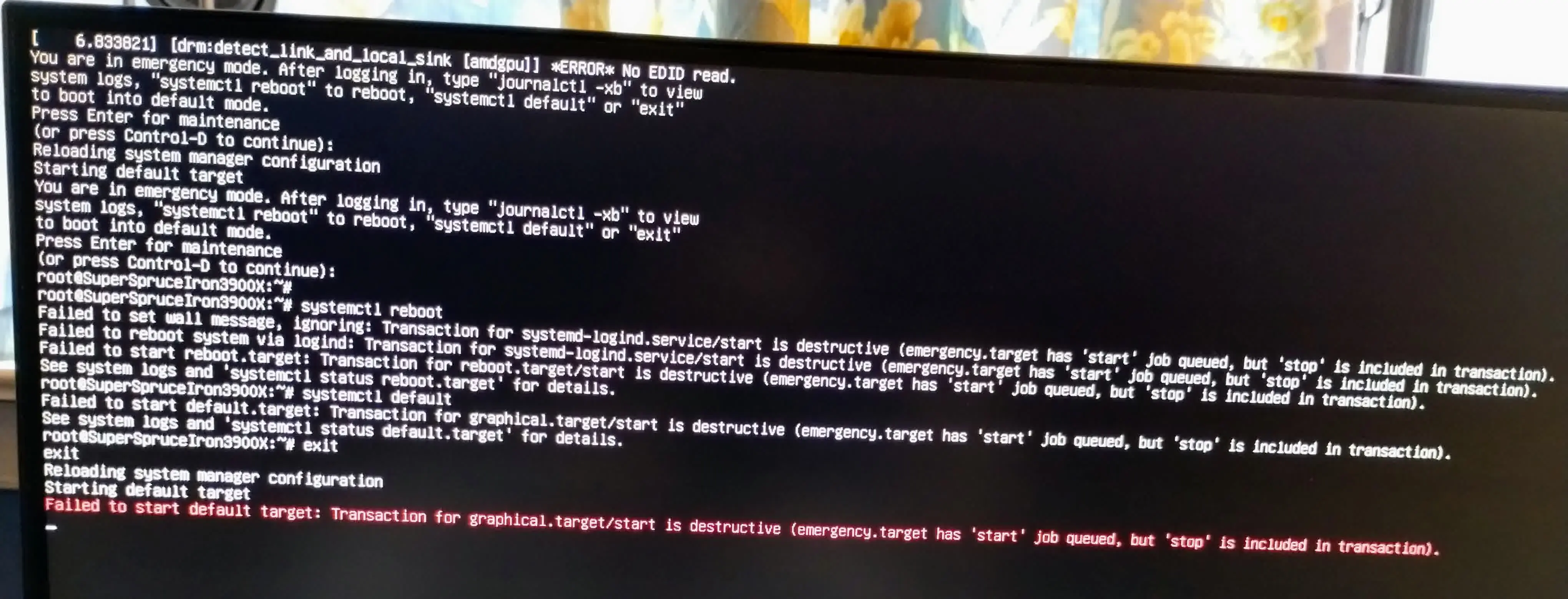
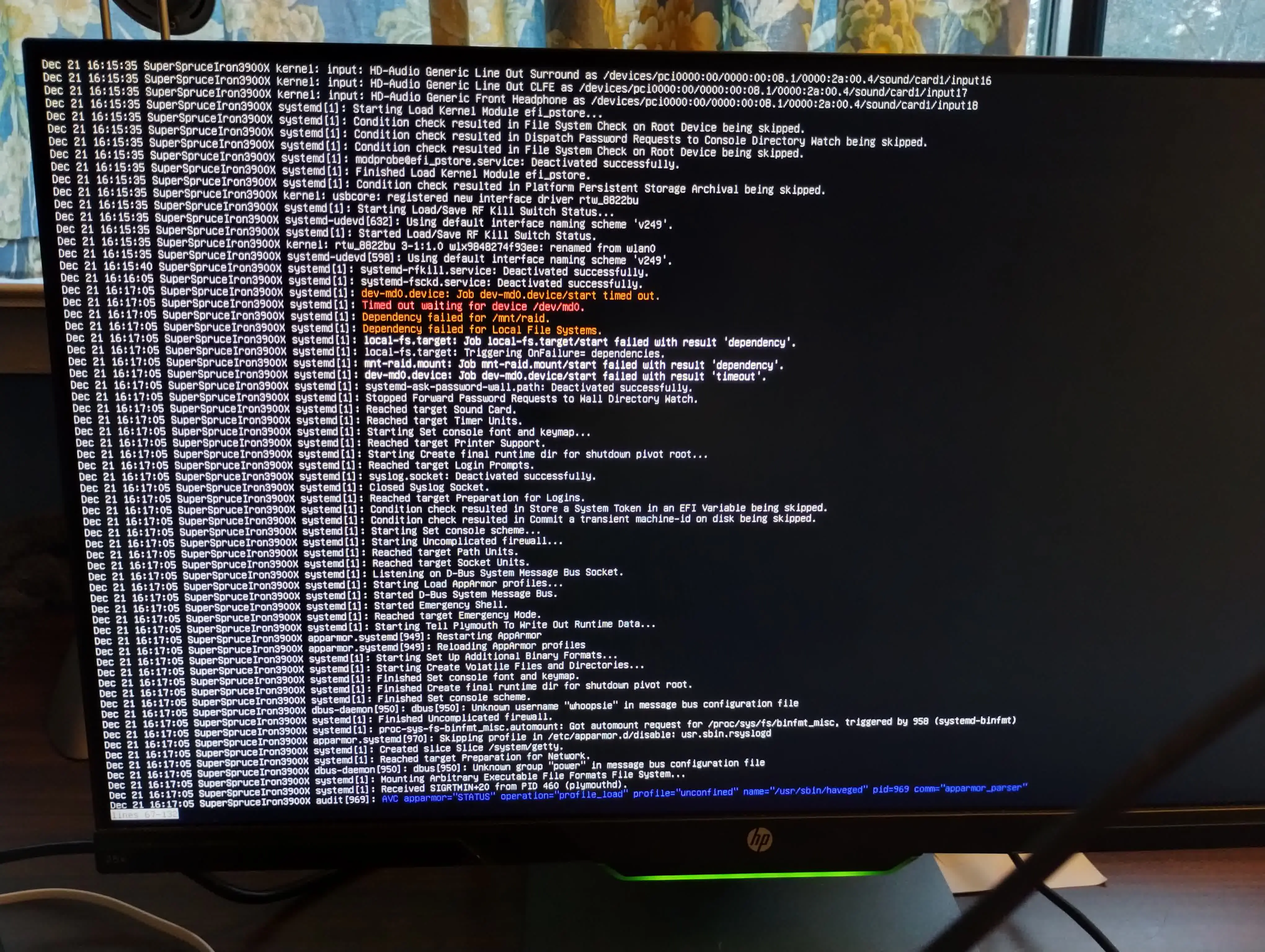
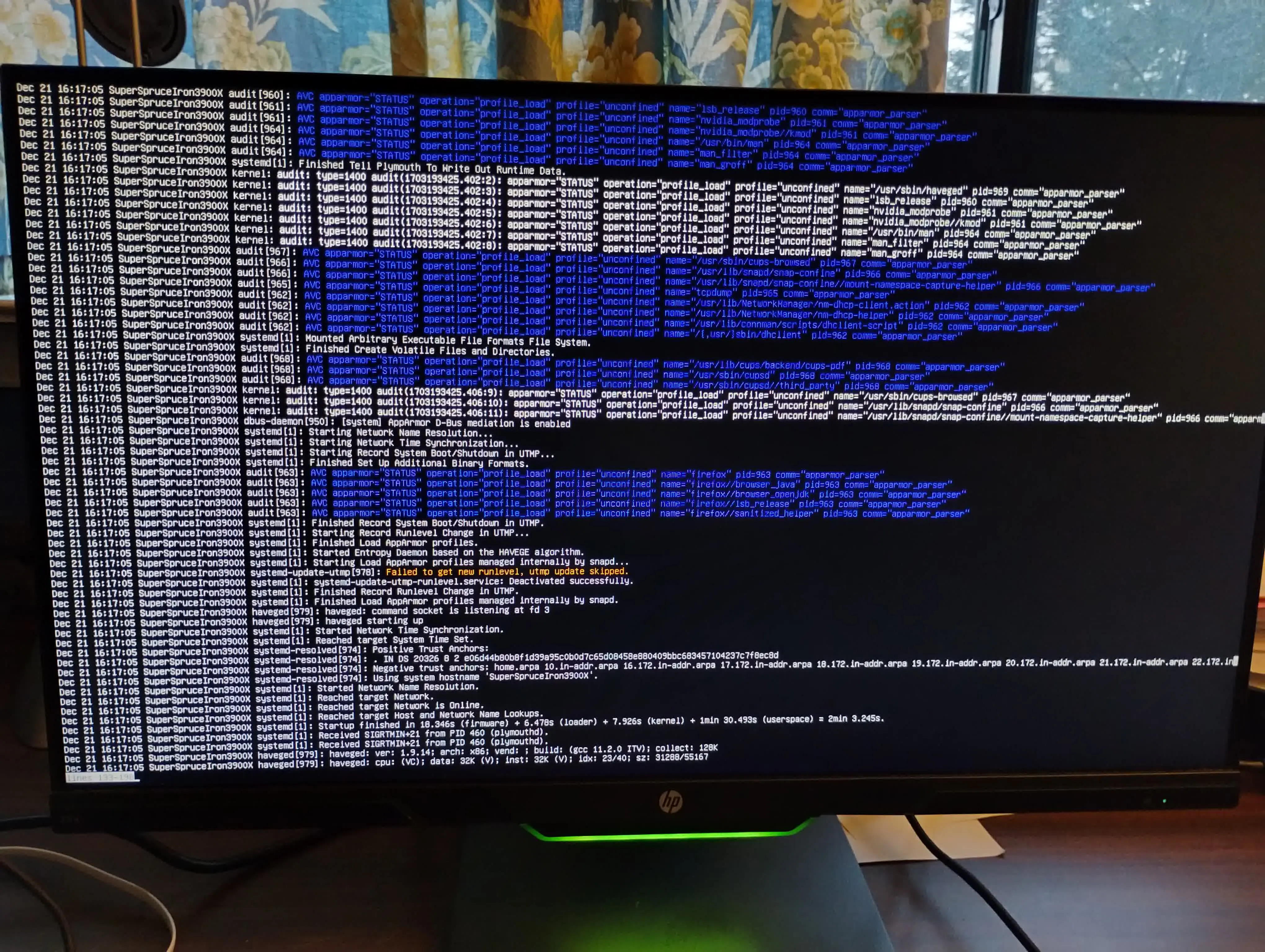
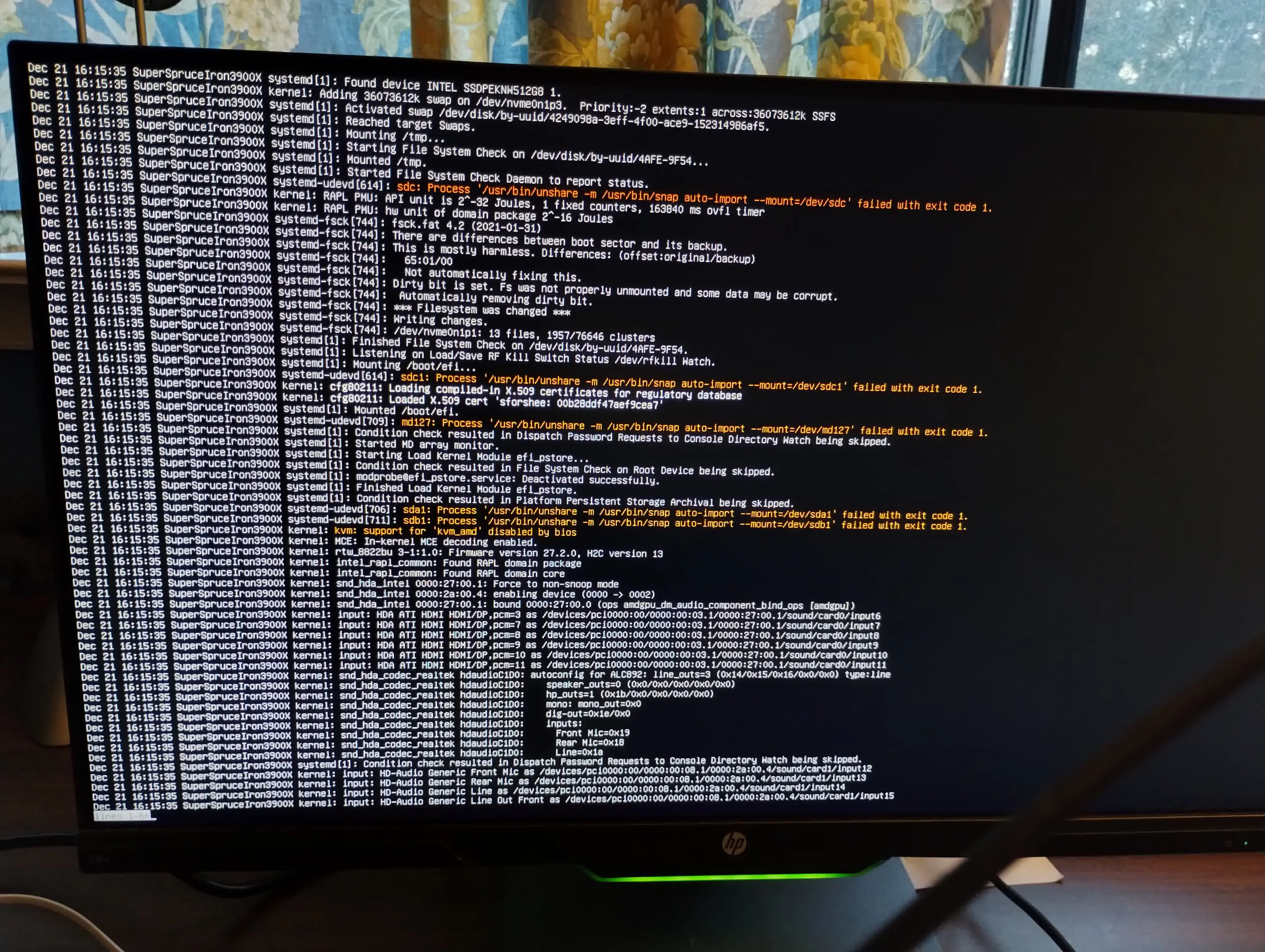
Then, even though it was working earlier today, it slept and then would not wake up. So I turned off the power and turned it back on again, and was greeted with this error screen:
The only prior error message I'd gotten from the system was when I tried to install wine for one application, it told me some packages weren't up to date, without a way to fix it. I can enter the BIOS just fine.
What is going on? How do I fix this?