ram
You'll have to keep waiting, all disney characters are trademarked.
I don't see how this is any different from adding another e-mail account on gmail.
These are the uBlock rules used to block the headers from youtube channels. The 'about' tab is intentionally left unfiltered for the cases I actually want to see that information.
https://pastebin.com/raw/MEUPPs0Z
edit: had to put the code on pastebin since the code markdown doesn't seem to work here.
Which one?
Adblockers can do more than just block ads, they also allow you to customize websites. As a simple example you can remove the annoying headers on youtube channels that take half the screen:
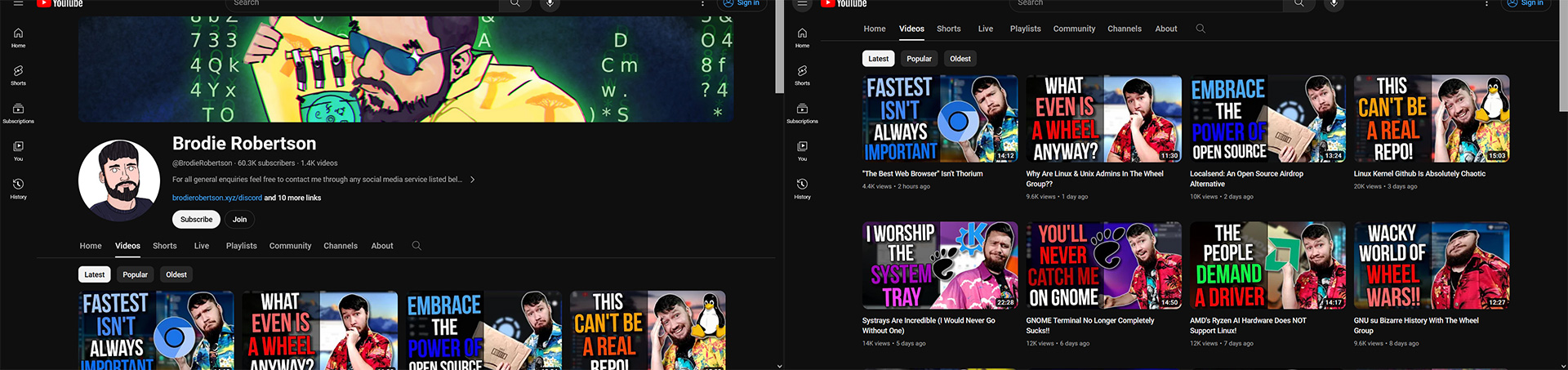
It's also great for news sites. I have a filter to remove articles on topics I don't care about. I also have rules to prevent these sites from automatically reloading after certain amount of time, something that I find very annoying.
special sauce they cooked it with let’s it run on the trashheap of a computer
It's called coding in VS C++ and using native Windows controls, a dying art form unfortunately. The price is losing cross-platform compatibility.
There are two Linux paradigms that I consider stupid. One is the use of centralized software repositories managed by the distro instead of individual developer maintained installers. The other one is file system case sensibility. They already admitted defeat on the first one with the rise of containerised applications. I wonder how much longer they'll keep the charade on the second one.
Everything is a neo-nazi hand sign.
Stress = I don't have a clue what's wrong with you
I was playing a Souls game while checking some info from Fandom on my phone. Unbeknownst to me the site was eating all my mobile data because of a live twitch stream playing on a muted and invisible player. Fuck those fuckers.
cross-posted from: https://yiffit.net/post/974332
Source: https://front-end.social/@fox/110846484782705013
Text in the screenshot from Grammarly says:
We develop data sets to train our algorithms so that we can improve the services we provide to customers like you. We have devoted significant time and resources to developing methods to ensure that these data sets are anonymized and de-identified.
To develop these data sets, we sample snippets of text at random, disassociate them from a user's account, and then use a variety of different methods to strip the text of identifying information (such as identifiers, contact details, addresses, etc.). Only then do we use the snippets to train our algorithms-and the original text is deleted. In other words, we don't store any text in a manner that can be associated with your account or used to identify you or anyone else.
We currently offer a feature that permits customers to opt out of this use for Grammarly Business teams of 500 users or more. Please let me know if you might be interested in a license of this size, and I'II forward your request to the corresponding team.
