118
Is anaconda download page considered dark pattern?
(lemmy.world)
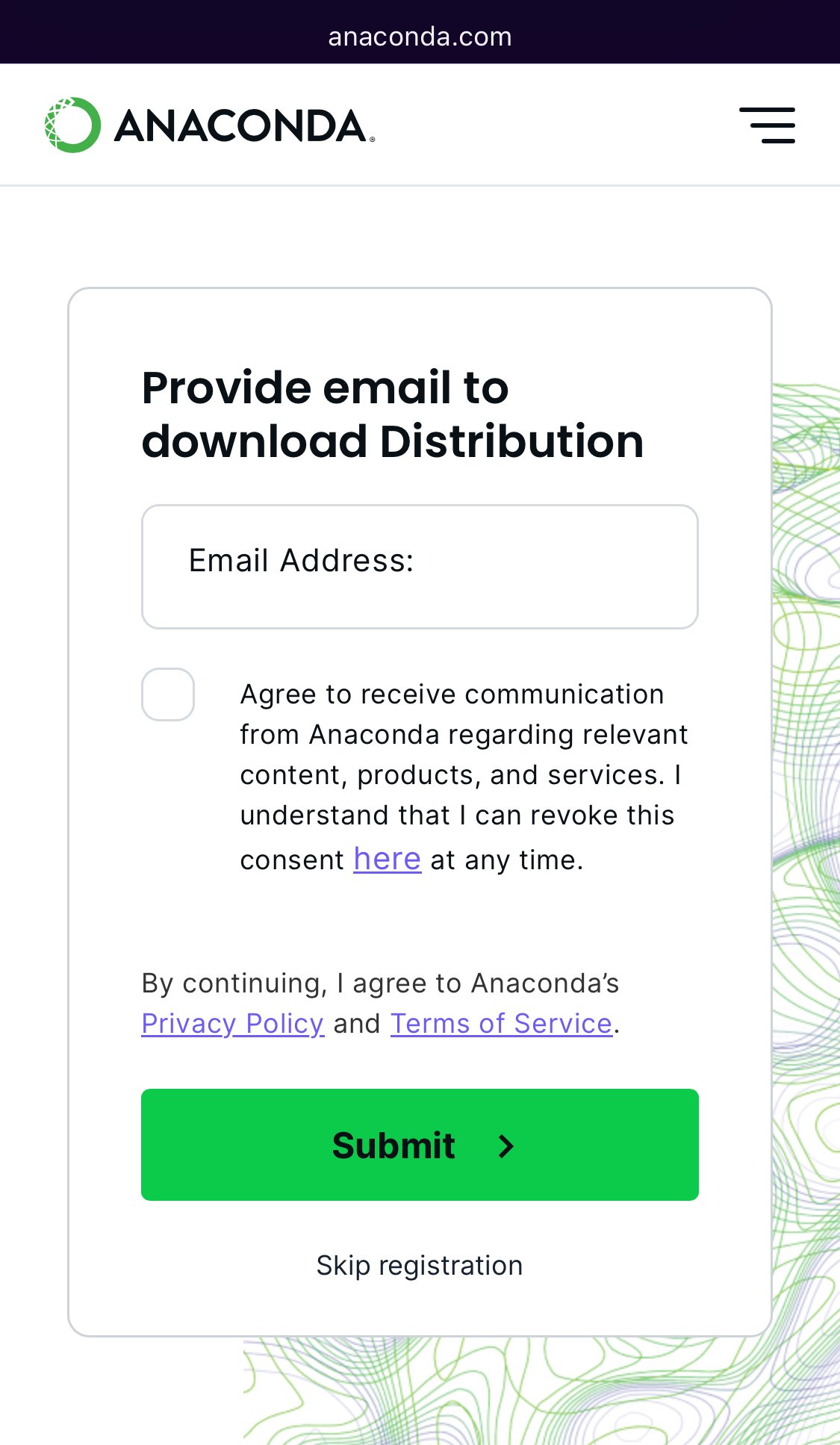
It’s been a while since I last downloaded anaconda. But I remember when clicking on the download page, it would show the usual “choose your OS > download binary” (eg this archived version in 2019).
Recently I helped someone else set it up and it showed a form to put on email, with smaller gray text near the bottom of the form about skipping it.
Does this count as a dark pattern?
thanks for clarifying! that’s really helpful!